RAID(Redundant Array of Independent Disks)即独立磁盘冗余阵列,通常简称为磁盘阵列。简单地说,RAID 是由多个独立的高性能磁盘驱动器组成的磁盘子系统,从而 提供比单个磁盘更高的存储性能和数据冗余的技术。
RAID 中主要有三个关键概念和技术:镜像(Mirroring)、数据条带(Data Stripping) 和数据校验(Data parity)。
- 镜像(Mirroring):
将数据复制到多个磁盘,一方面可以提高可靠性,另一方面可并发从两个或多个副本读取数据来提高读性能。但为了确保数据正确的写到多个磁盘需要更多的时间消耗,因此镜像的写性能要稍低。 - 数据条带(Data Stripping):
将数据分片保存在多个磁盘,多个数据分片共同组成一个完整的数据副本。数据条带具有更高的并发粒度,当访问数据时,可以同时对位于不同磁盘上的数据进行读写操作,从而获得非常可观的I/O性能提升。 - 数据校验(Data parity):
利用冗余数据进行数据错误检验和修复,冗余数据通常采用海明码、异或操作等算法来计算获得。利用校验功能,可以很大程度上提高磁盘阵列的可靠性和容错能力。不过,数据校验需要从多个地方读取数据进行计算和对比,会影响系统性能。
对应以上三种关键概念技术,RAID被分为了三个基础形式:
- RAID0-数据条带,代表了所有RAID中最高的存储性能
RAID 0没有数据冗余、没有奇偶校验。因此,如果一个硬盘坏掉了,整个RAID阵列的数据都没法正常使用了。它存在的意义在于加快读写速度,提升硬盘容量。通常在数据可靠性要求不高的情况下才会使用RAID 0。比如游戏、科学计算。 因为每个硬盘都可以独立读写,如果硬盘有n块,那么读写速度提升是n倍。
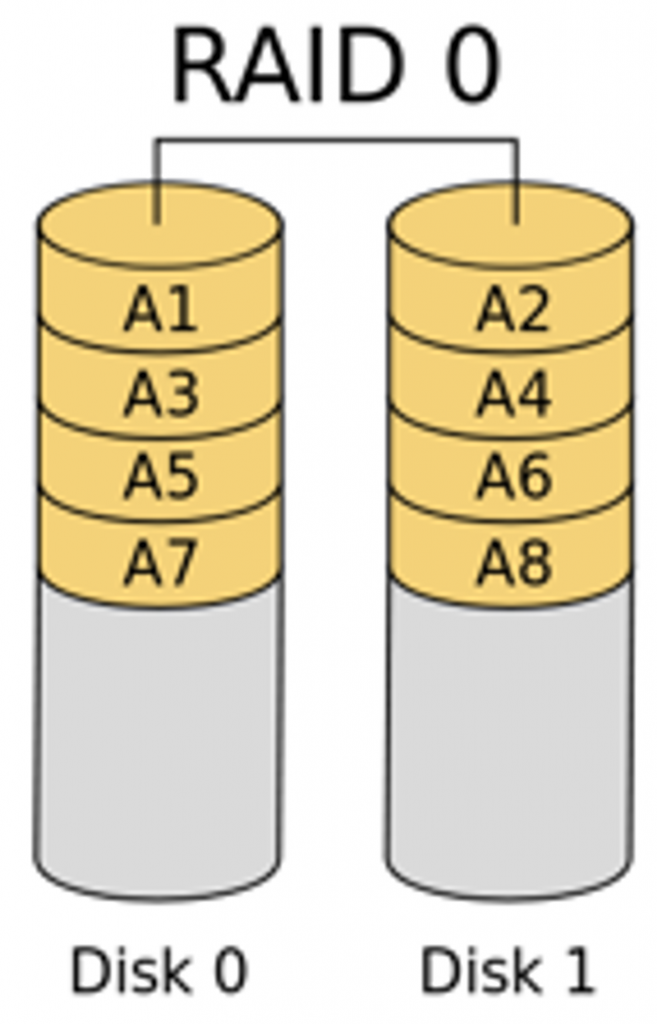
如上图:我们如果需要存储A1-8,那么在RAID0下,我们的存储将会是A1放于第一块DISK上,A2放于第二块DISK上,A3放于第一块DISK上,以此类推,因此,RAID0的磁盘利用率将会是100%
- RAID1-镜像,最大限度保证用户数据的可用性和可修复性
RAID 1模式下,如果有n块硬盘,那么会把数据保存n份一模一样的。这样即使一份数据坏掉了,剩下的备份可以正常工作。性能方面,随机存取速度相当于所有硬盘的总和,写入性能和原来单个硬盘的性能一样。
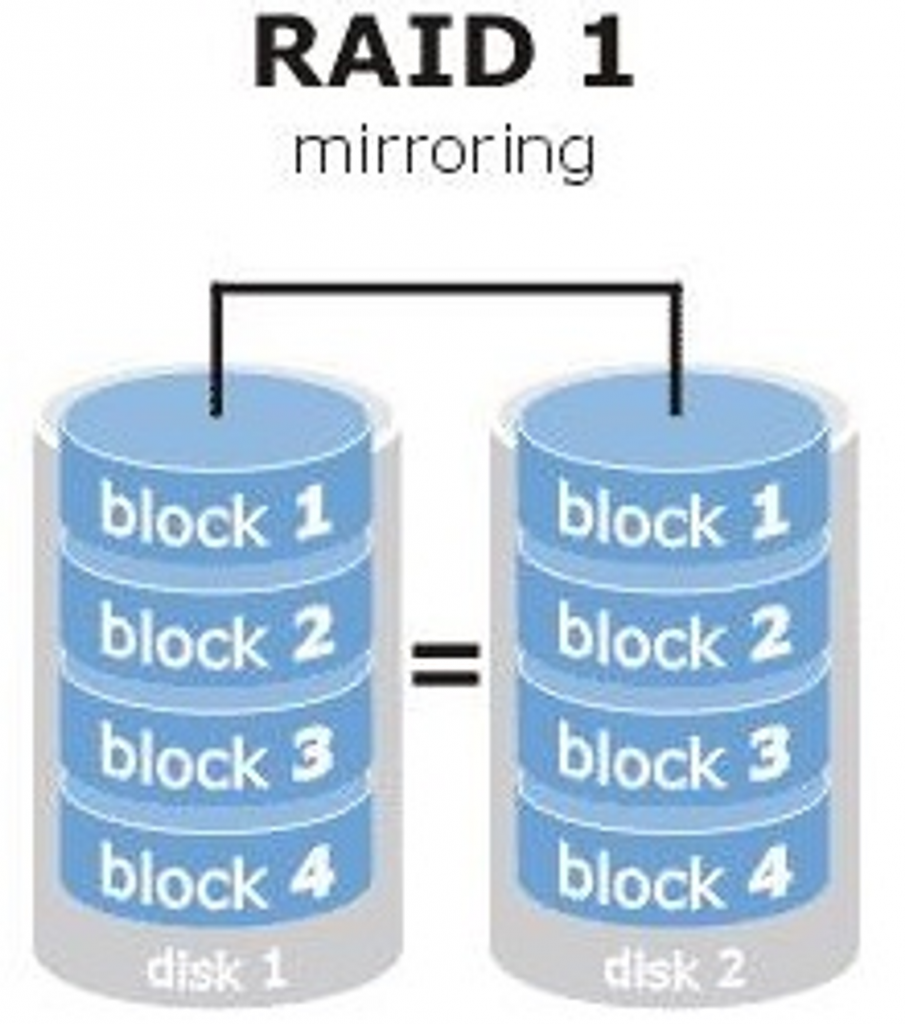
如上图:我们如果需要存储block1-8,那么在RAID1下,我们的存储将会是block放于第一块DISK上,与此同时,磁盘会自动产生一份新的block1,备份于第二块DISK上,因此,RAID1的磁盘利用率将会是1/n(n是进行RAID1操作的磁盘数量),即上图的磁盘利用率是1/2=50%
- RAID5-数据校验,检验码均匀分布,最多坏一块磁盘
这种模式把每个数据块打散,然后均匀分布到各个硬盘。与RAID-4不同的是,它将奇偶校验的数据均匀的分散到不同的硬盘。这样如果有一个硬盘坏掉了,丢失的数据可以从奇偶校验里面计算出来。 通常RAID-5的容量会损失一部分,用来储存奇偶校验信息。 这种模式兼顾了成本、性能、伪冗余,也是比较常用的一种模式。
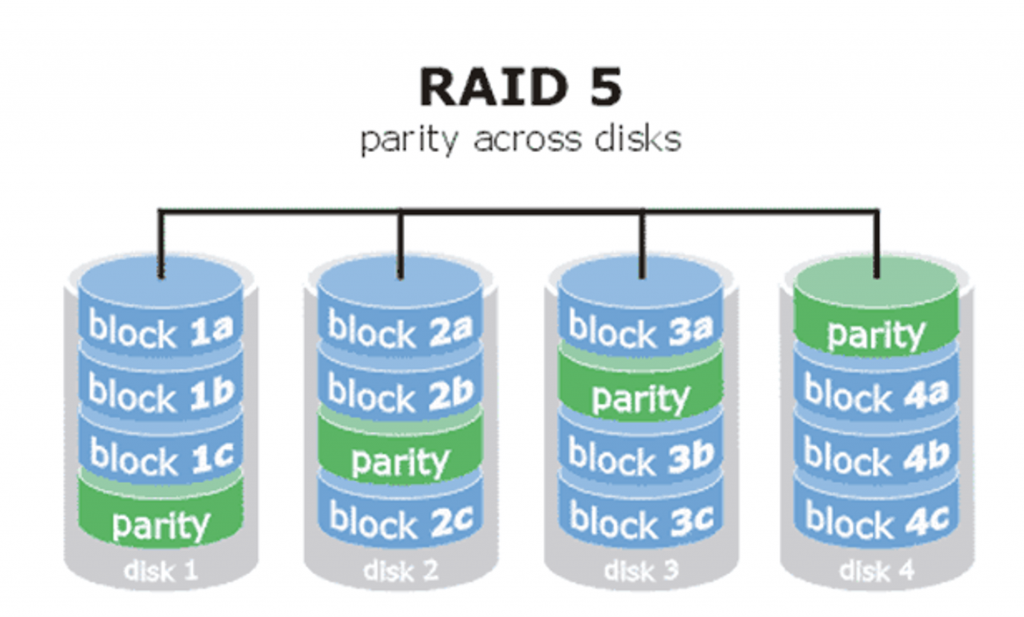
如上图:“parity”部分存放的就是数据的奇偶校验信息,换句话说,就是RAID5技术实际上没有备份磁盘中的真实数据信息,不存在冗余操作,而是当硬盘设备出现问题后通过奇偶校验信息来尝试重建损坏的数据,由上图可以推导RAID5的磁盘利用率为(n-1)/n(n是进行RAID5操作的磁盘数量),即如上图的利用率为:(4-1)/4=3/4=75%。
又根据情况的不同的情况以及更新迭代,产生了以下几种:
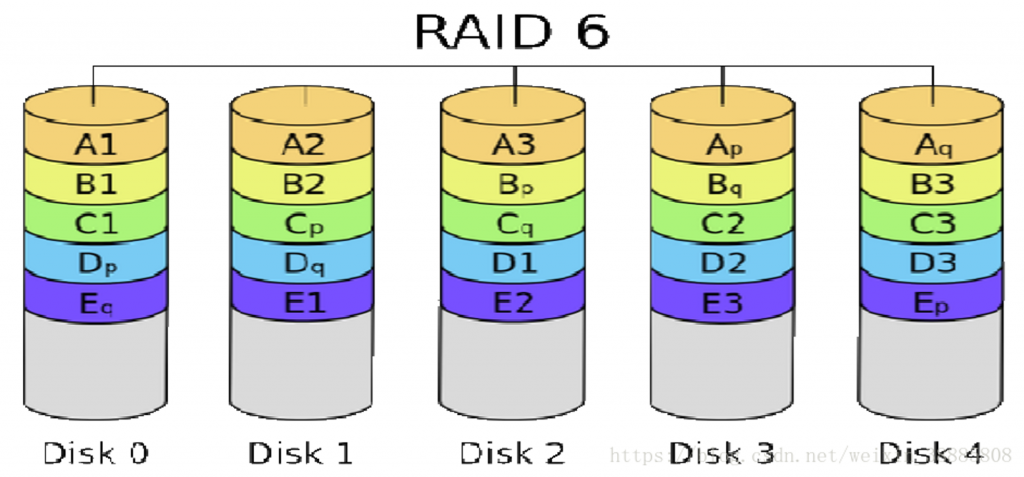
- RAID6: 两组校验,检验码均匀分布,最多坏两块磁盘
这种模式与其他模式的区别在于,它支持两块硬盘同时损坏,并且仍然能够正常工作。它有这般神奇的能力,是因为它保存了两种奇偶校验。一种是普通的XOR方式,跟RAID-5一样。另外一种比较复杂,需要消耗比较多的CPU。
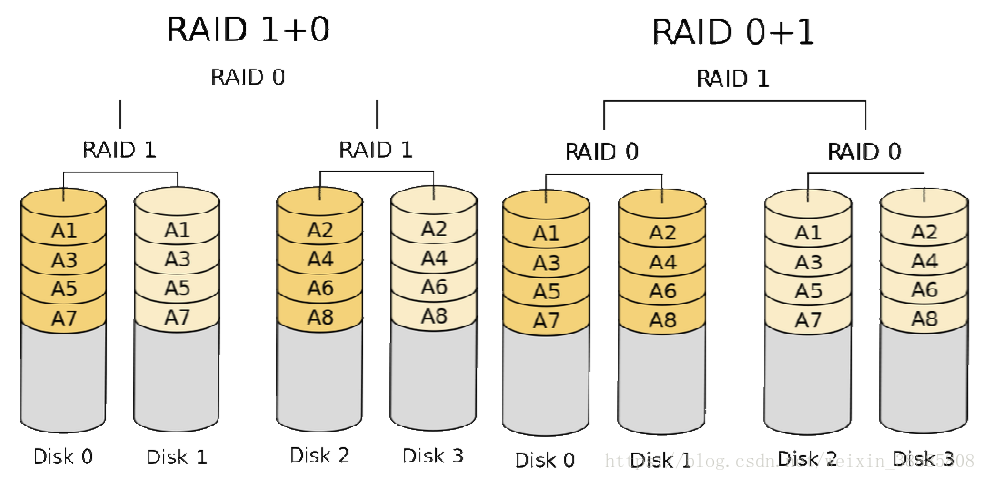
- RAID10:先镜像再条带
它相当于先把这些硬盘成对成对的用RAID-1方式组合起来,然后再把这些组合结果用RAID-0方式组合起来。这种模式下它支持高可用,又能有很好的读写性能。这种方式,由于需要存两份一模一样的数据,因此容量会损失一半。 这种方式是目前最常用的。
- RAID01: 先条带再镜像,
与10相当的原理,不过其为先进行RAID-0组合,在进行RAID-1组合,但是这种组合方式存在一定的问题,在后续进行比较时再详细说明
实际上RAID技术也存在过1E、2、3、4这几种,但是已经被淘汰或是弃用了
对于RAID10和RAID01的比较
安全性方面的差别:
- RAID10的情况:假设当DISK0损坏时,在剩下的3块磁盘中,只有当DISK1也发生故障时,才会导致整个RAID失效,我们可以简单计算故障率为1/3。
- RAID01的情况:假设DISK0损坏,这是左边的条带无法读取,在剩下的磁盘中,只要DISK2和DISK3中任何一块磁盘损坏,都会导致整个RAID失效,我们可以计算故障率为2/3。 因此,RAID10在安全性方面要比RAID01强。
性能方面差别:
从数据存储的逻辑位置来看,在正常情况下,RAID10和RAID01是完全一样的,而且每一个读写操作所产生的I/O数量也是一样的,所以在读写性能上,两者没有什么区别。而当磁盘出现故障时,比如DISK0损坏,可以发现,在读写性能上将有所差异,RAID10性能要优于RAID01。
所以从逻辑判断来看,RAID10优于RAID01
创建RAID列阵
mdadm指令
mdadm是一个用于创建、管理、监控RAID设备的工具,它使用linux中的md驱动。
mdadm程序是一个独立的程序,能完成所有软件RAID的管理功能,
常用参数:
参数 作用
-a: 检测设备名称
-n :指定设备数量
-l :指定RAID级别
-C :创建
-v :显示过程
-f :模拟设备损坏
-r :移除设备
-Q :查看摘要信息
-D :查看详细信息
-S :停止RAID磁盘阵列
- 关于参数-a的释义: 创建md设备文件。选项是{no,yes,md,mdp,part,p}{NN}。默认是yes。 “yes”要求RAID设备名是标准格式的,然后设备文件类型和minor号会自动确定。 比如RAID设备名是”/dev/mdx” 查看/proc/partitions可以看到mdx的major号是9,minor号是x。 当使用”md”时,RAID设备名可以是非标准格式,比如”/dev/md/zhu”,然后创建两个设备文件/dev/md/zhu 还有 /dev/mdx,并给这两个设备文件分配相同的major号和minor号(也就是这两个设备文件指向同一个设备)。分配minor号的方法是:分配一个没有使用过的minor号,这个minor号就是/dev/mdx中的数字x。查看/proc/partitions和/proc/mdstat,RAID设备名还是/dev/mdx。 当使用”mdp,p,part”时,RAID设备名可以是非标准格式,比如”/dev/md/zhu”,除了创建设备文件/dev/md/zhu 还有 /dev/mdx外,还会创建 /dev/md/zhup1, /dev/md/zhup2, /dev/md/zhup3, /dev/md/zhup4,这些是分区设备文件。
示例创建一个RAID10阵列:
mdadm -C /dev/[新建立的阵列名称] -l [RAID等级] -n [被使用的磁盘分区的数量] [各个指定的磁盘分区]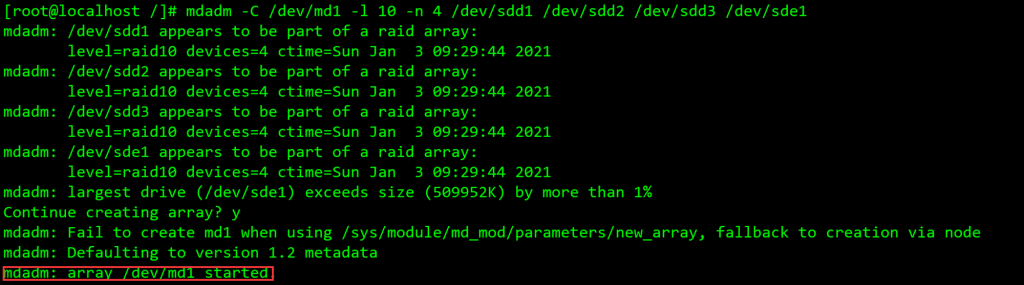
注意:
- 上图为测试环境多次删除重建显示的报警(大致为sdd1-3与sde1已经被md操作过一次,请求操作者确认是否要继续),我们在使用时,只要显示了最后一行被标识的字段,即可以视为成功
- 在此的设备参数:/dev/md1 /dev/sdd1 /dev/sdd2 /dev/sdd3 /dev/sde1共计五个设备。实际上在此处都是**目标对象,**并非仅仅是参数,所以,我们只需要注意在构写指令时,让作为新建md阵列名称的/dev/md1在第一个被识别即可
- 在建立md设备时,其所属的分区不需要分配文件系统更不用挂载,我们将其合并成md设备后,再将md设备分配文件系统和挂载即可
在创建md阵列时,我们会考虑优先使用其最兼容的名称(即md+数字的组合形式,例如:md1、md10…),但是在某些特殊情况下,我们也会使用一些特殊形式的md设备名称(非md+数字组合的形式),在这种情况下,我们写入的新建md设备名不可以再写成**/dev/设备名**的形式,而需要将其写成至**/dev/md/设备名**的形式,不然将会导致创建失败。
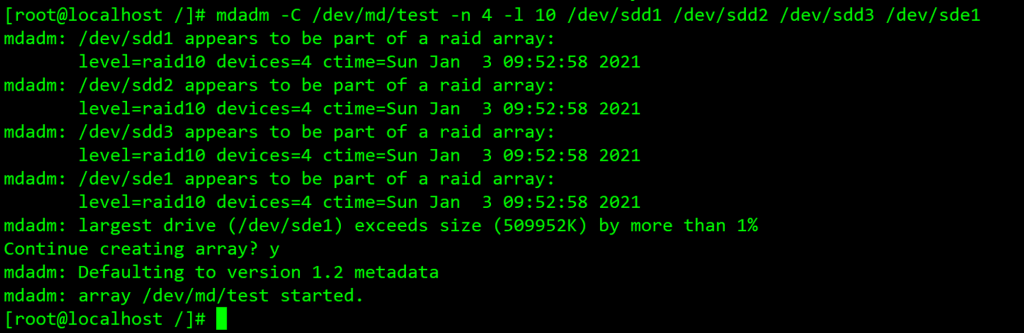
一些特殊形式的报错显示:
1.使用字母形式:
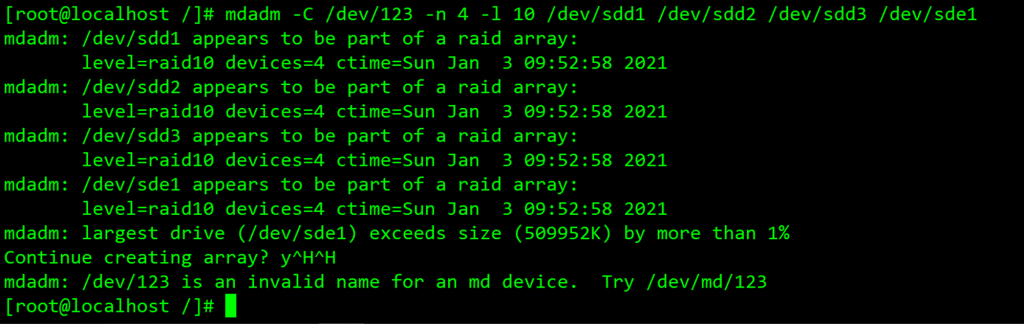
2.使用数字形式:
3.使用标准化md关键字加其他特殊字符:
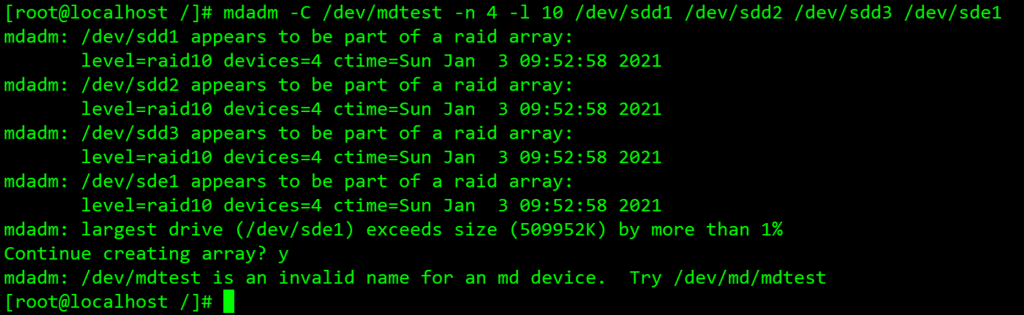
如上三个示例可以看见,违反创建名规则就不允许创建于/dev下!
特殊名称创建示例:
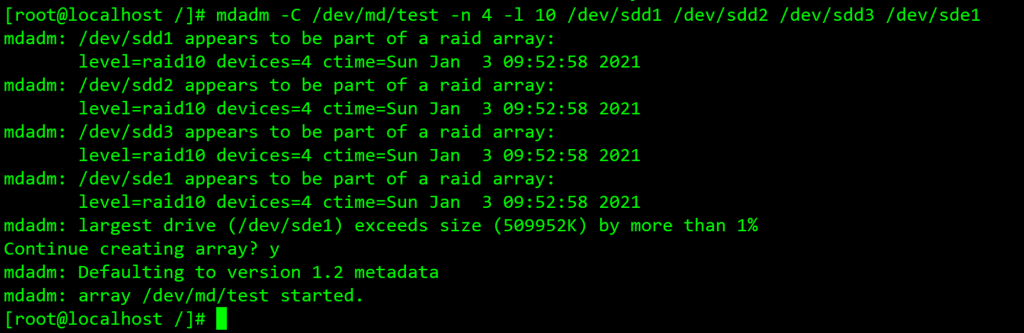
当我们创建MD设备成功后,特殊名称的md设备会被自主的创建一个标准名称形式保留在/dev目录下,如下显示:
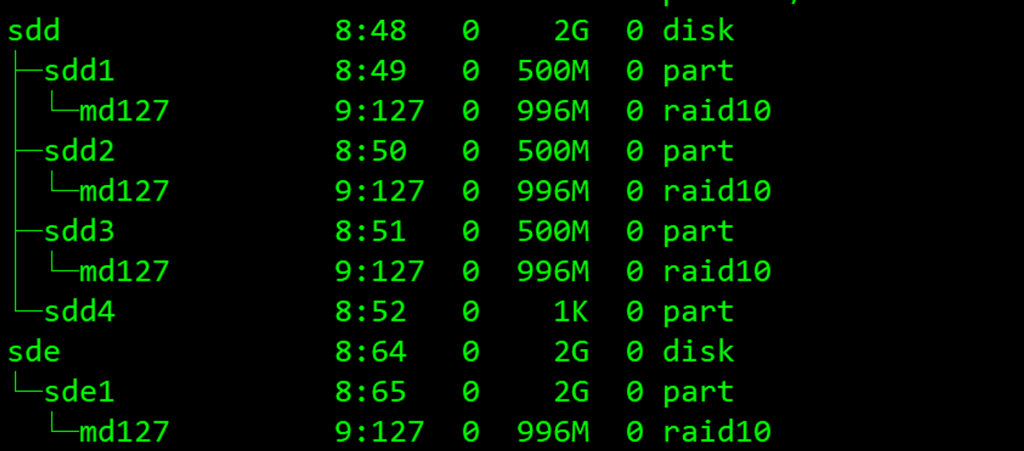
承接上文,我们创建了一个名称为test的md设备,但是使用lsblk命令后,我们可以发现,几个所属的文件管理系统都是隶属于**md127**的,其实在并不是什么错误,而是系统自动将我们的test命名为了md127保留于/dev下,这里的md127就是test设备,以后系统显示test设备都会优先考虑md127这个系统认可的名称:
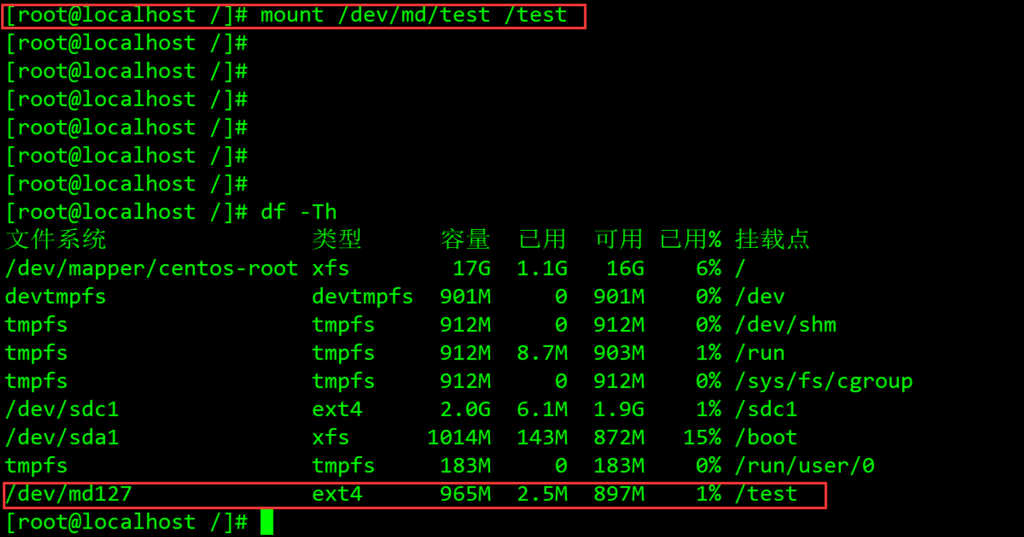
有关取消md列阵:
在建立md列阵之后,我们可以使用mdadm -S [目标md设备名]来取消掉这个操作(需要提前将其取消挂载):
注意:在取消了列阵操作后,其所属的文件管理系统下存在的数据不会被丢弃!