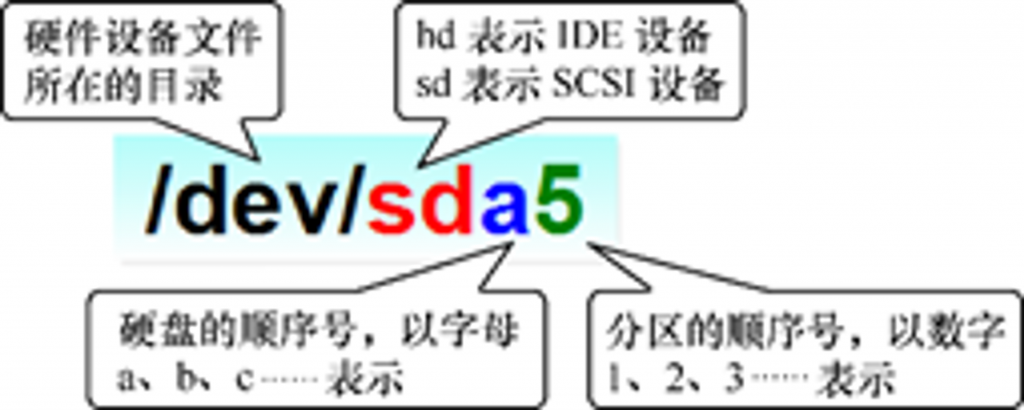
Linux下的磁盘设备命名规则
我们都知道,在linux系统之中有着**一切皆文件**的规则,在linux下,我们的硬件设备也以文件的形式被存放在了/dev目录之下,并且拥有着它自己的命名规则。
在此,我们给出根据硬盘的硬件种类来区分的规则:
- IDE设备 :hd[a、b、c….][1、2、3…]
- SCSI/SATA/U盘设备:sd[a、b、c….][1、2、3…]
我们拿IDE设备来解释这里的字符串hd[a、b、c….][1、2、3…]:
首先,hd代表的是IDE设备磁盘的特殊符号,若我们查看到我们的硬盘在Linux中显示为hd开头,则几乎可以断定是IDE设备硬盘
其次的**[a、b、c….]字符串代表了这是一个linux系统中的第几块IDE磁盘**,第一块为a,第二块为b,第三块则为c,以此类推……
最后的**[1、2、3…]字符串则代表了这是一块IDE磁盘上的第几个分区**,第一个分区为1,第二个分区为2,第三个分区为3,以此类推……
例如,我们拥有一块先行装入安装系统的SATA磁盘,又后置了一块IDE磁盘,那么我们分别区分其第一和第三分区应该为:
- SATA:sda1/sda3
- IDE:hdb1/hdb3
扩展:
这里给出一些其他设备的命名方式:
- 软驱: fd[0-1]
- 光驱 : cdrom
- 鼠标 : mouse
- 磁带机 : st0或 ht0
Linux下的磁盘分区方式
硬盘分区表是支持硬盘正常工作的架构。其意义在于操作系统会根据硬盘的分区表把硬盘划分为若干个分区,然后再在每个分区里面创建文件系统,使系统可以写入数据。不同的硬盘分区表就像是对一个房子的不同的装修方案。
一般来说,在Linux下的分区方式,主要有两种:
- MBR
MBR全称为Master Boot Record
主引导记录,是传统的分区机制,应用于绝大多数使用BIOS的PC设备
MBR+BIOS
MBR支持32位和64位系统。
MBR支持分区数量有限。
MBR只支持不超过2T的硬盘,超过2T的硬盘将只能用2T空间(有第三方解决方法)。
简单来说,MBR分区只支持2T以下的硬盘进行分区,使用fdisk指令,并且MBR在分区时,只能够分出4个分区(4个主分区或者3个主分区加一个扩展分区,逻辑分区应建立于扩展分区之上)
- GPT
GPT(GUID Partition Table)
全局唯一标识分区表,是一个较新的分区机制,解决了MBR很多缺点。
支持超过2T的磁盘(64位寻址空间)。fdisk最大只能建立2TB大小的分区,创建一个大于2TB的分区使用parted。
向后兼容MBR。
必须在支持UEFI的硬件上才能使用(Intel提出,用于取代BIOS)。
GPT+UEFI
必须使用64位系统。
Mac、Linux系统都能支持GPT分区格式。
Windows 7/8 64bit、Windows Server 2008 64bit支持GPT。
GPT分区可以支持2G以上的硬盘分区,使用parted指令,并且GPT可以无限制进行分区
以上就是Linux系统MBR和GPT分区的区别,总得来说GPT比MBR更先进,但是MBR的兼容性比GPT要好,但当今我们一般仍然选择使用MBR分区
Linux下的文件管理系统
如果我们将磁盘的分区比作是将一栋楼房划分成了各个楼层,那么文件管理系统则代表了各个楼层所使用的装修风格,视实际情况和个人习惯等因素,各个楼房的装修风格也会随之改变。同理,文件管理系统则是每一个分区下的文件管理方式,它决定了该磁盘分区下文件该如何存储,在不同的情况以及不同的使用者喜好下,我们可以选择不同的文件管理系统。
如今Linux下常用的文件管理系统有如下几种:
Ext3(实际上也不怎么使用了) 是一款日志文件系统,能够在系统异常宕机时避免文件系统资料丢失,并能自动修复数据 的不一致与错误。然而,当硬盘容量较大时,所需的修复时间也会很长,而且也不能百分 之百地保证资料不会丢失。它会把整个磁盘的每个写入动作的细节都预先记录下来,以便 在发生异常宕机后能回溯追踪到被中断的部分,然后尝试进行修复。
Ext4 Ext3的改进版本,作为RHEL 6系统中的默认文件管理系统,它支持的存储容量高达 1EB(1EB=1,073,741,824GB),且能够有无限多的子目录。另外,Ext4文件系统能够批 量分配block块,从而极大地提高了读写效率。
XFS 是一种高性能的日志文件系统,而且是RHEL 7中默认的文件管理系统,它的优势在发生意 外宕机后尤其明显,即可以快速地恢复可能被破坏的文件,而且强大的日志功能只用花费 极低的计算和存储性能。并且它最大可支持的存储容量为18EB,这几乎满足了所有需 求。
一般来说,我们会在给一个分区进行格式化或者初定义的时候,给其定义一个新的或者原来使用的文件管理系统
我们都知道,Linux中的文件不仅仅拥有着它被存储的内容,也拥有者它自己的**属性,**虽然不是我们经常需要查看的内容,但是这也并不能否定属性也是文件内容的一部分这个事实。
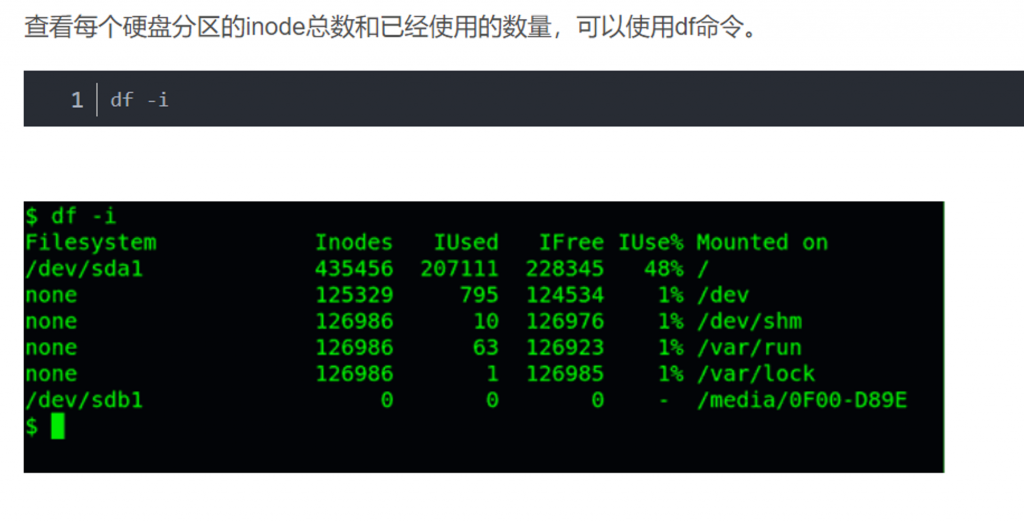
在linux中,文件管理系统通常会将这两部份的资料分别存放在不同的区块,它将文件的属性放置到inode中,而至于实际资料则放置到data block区块中。另外,还有一个超级区块(superblock)会记录整个档案系统的整体信息,包括inode与block的总量、使用量、剩余量等。
inode号只在同一文件系统中是唯一的!!!
每个inode 与block 都有编号,至于这三个资料的意义可以简略说明如下:
- superblock:记录此filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件管理系统的格式与相关信息等;
- inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的资料所在的block 号码;
- block:实际记录文件的内容,若文件太大时,会占用多个block 。
关于inode,我们需要注意:
inode包含文件的元信息,具体来说有以下内容:
- Size 文件的字节数
- Uid 文件拥有者的User ID
- Gid 文件的Group ID
- Access 文件的读、写、执行权限(以及三种特殊权限)
- 文件的时间戳,共有三个:
- Change 指inode上一次变动的时间
- Modify 指文件内容上一次变动的时间
- Access 指文件上一次打开的时间
- Links 链接数,即有多少文件名指向这个inode
- Inode 文件数据block的位置
- Blocks 块数
- IO Blocks 块大小
- Device 设备号码
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。 每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
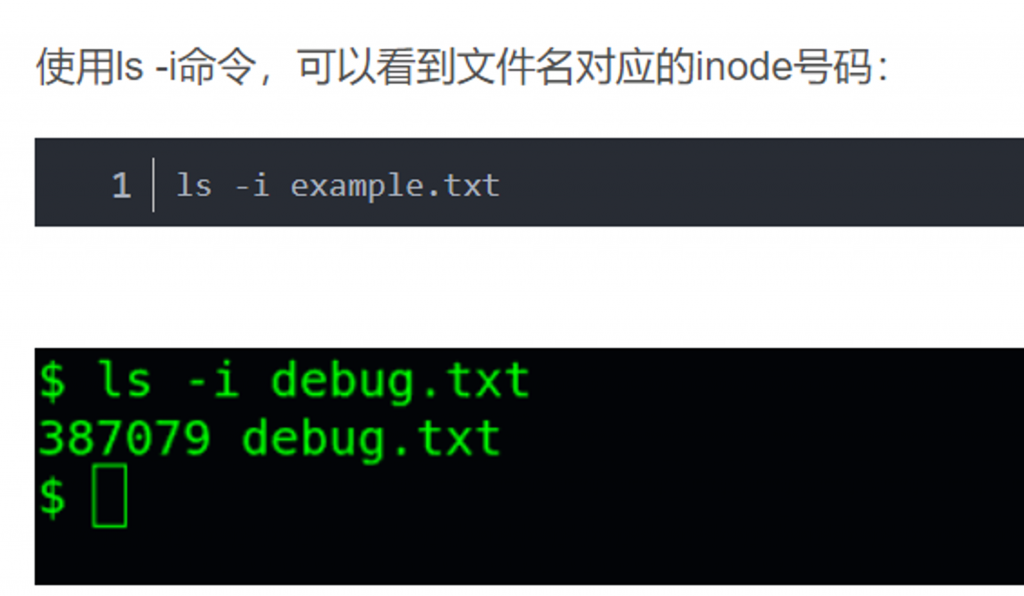
每个inode都有一个号码,操作系统用inode号码来识别不同的文件,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于用户识别的别称或者绰号。
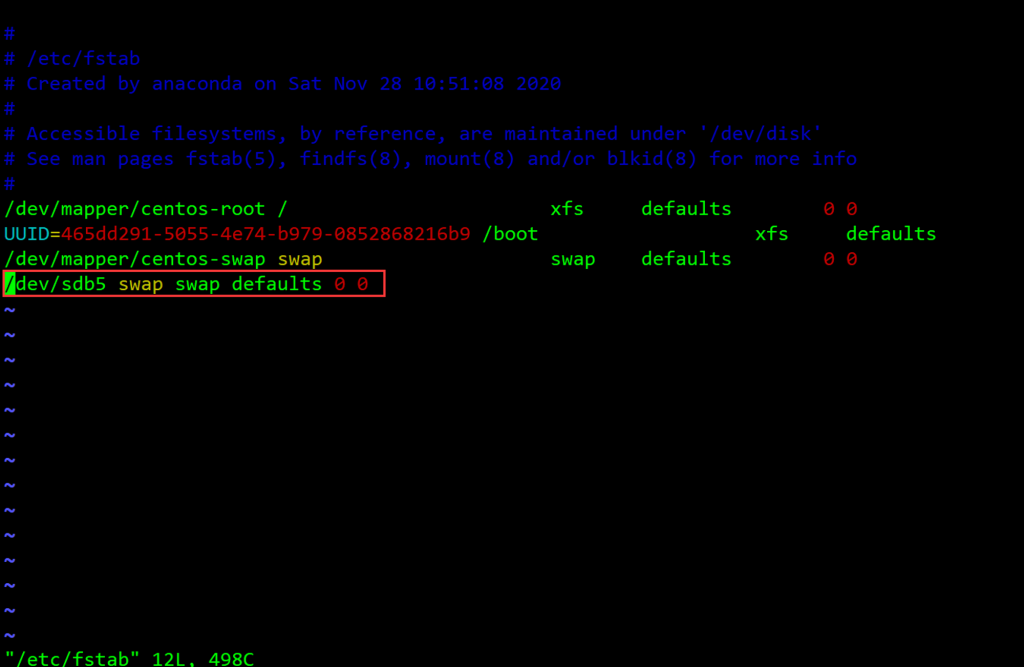
swap分区
Swap分区,即交换区,系统在物理内存(这里应该是运行内存)不够时,与Swap进行交换(与Windows下的虚拟内存相似)。 其实,Swap的调整对Linux服务器,特别是Web服务器的性能至关重要。通过调整Swap,有时可以越过系统性能瓶颈,节省系统升级费用。一般来说,swap分区的大小应该是物理内存的1.5-2倍,但这并不绝对,实际情况要视需求而定。
使用free -h指令检查机器本身的已有swap分区总大小以及内存大小,以及它们的使用情况:

使用mkswap指令将一个分区初定义或者格式化成swap分区格式:

使用swapon指令将指定swap分区启用,并使用free -h指令查看启用新swap分区后,swap分区的总大小:

如上所示,我们的swap分区总大小从2G变成了2.5G,若想要禁用指定swap分区,可以使用swapoff指令:
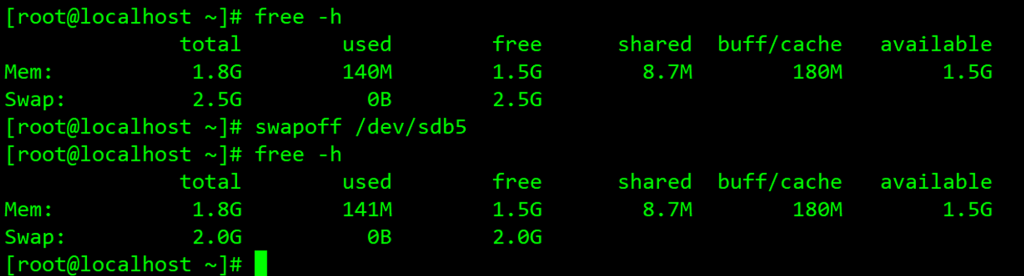
和普通的分区一样,使用指令进行的分区操作,并不能使swap分区永久生效,一旦重启或者意外断电,该swap分区将会失效,想要实现永久生效的swap分区,需要进入fstab文件中,将swap分区信息写入改文件并保存启用: